LLM(Large Language Model)
LLM(Large Language Model)은 대규모 데이터셋을 기반으로 학습된 인공지능 언어 모델로, 자연어 처리(NLP) 분야에서 주목받고 있다. 이번 글에서는 LLM의 개요 및 발전 배경, LLM의 작동 원리, 대표적인 LLM 모델에 대해서 살펴보려고 한다.
1. LLM의 개요 및 발전 배경
LLM은 사람의 언어를 이해하고 생성하는 데 뛰어난 성능을 발휘하며 최근 몇 년 간 급격히 발전해왔다. 특히 Transformer 아키텍처의 발전은 LLM의 기본 틀을 제공하였고, 이로 인해 모델들은 더 많은 데이터를 처리하고 더 복잡한 언어적 패턴을 학습할 수 있게 되었다. 2022년 11월 30일에 등장한 OpenAI의 ChatGPT는 IT 업계를 뒤흔들었으며, 이 챗봇 AI는 인간 피드백을 기반으로 한 강화학습(RLHF)를 통해 성능을 높였다. 그 결과 사람과 유사한 수준의 답변으로 놀라움을 안겨주었다.

2. LLM의 작동 원리
LLM은 주로 Transformer 아키텍처를 기반으로 하며, 이 아키텍처는 다음과 같은 주요 요소로 구성된다.
1. 토큰화(Tokenization)
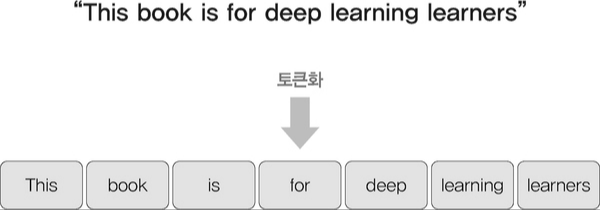
토큰화는 입력 문장을 단어 또는 서브워드(subword) 단위로 분리하는 과정이다. 이 과정에서 입력된 텍스트는 '토큰'으로 변환되며, 이러한 토큰들은 모델이 이해하고 처리할 수 있는 형태로 변환된다. 서브워드 방식은 언어의 다양한 형태를 효과적으로 처리할 수 있어, 드물게 사용되는 단어도 잘 표현할 수 있다. 예를 들어, "unhappiness"라는 단어는 "un", "happi", "ness"와 같은 서브워드로 나눌 수 있다. 이로 인해 모델은 다양한 어휘를 더 잘 이해할 수 있다.
2. 임베딩(Embedding)
임베딩 과정에서는 각 토큰이 고차원 벡터로 변환되어 의미를 부여받는다. 이 단계에서 각 토큰의 의미를 수치적으로 표현하는 방법이 사용되며, 단어 간의 관계를 반영할 수 있도록 설계된다. 예를 들어, "왕"과 "여왕"의 임베딩 벡터는 서로 가까운 위치에 있어 이들 간의 관계를 나타낸다. LLM에서는 훈련 과정에서 학습된 벡터를 사용하여 각 단어의 의미를 효과적으로 표현한다.

3. 어텐션 메커니즘(Attention Mechanism)
어텐션 메커니즘은 입력 시퀀스 내의 단어 간 관계를 파악하여 정보를 종합하는데 도움을 준다. 특히 '셀프 어텐션' 기법을 통해 각 단어가 다른 단어에 얼마나 주의를 기울여야 하는지를 결정한다. 예를 들어, "그녀는 사과를 좋아한다"라는 문장에서 "그녀"가 "사과"와 어떤 관계가 있는지를 이해하는 과정이다. 이 과정은 각 단어의 중요도를 평가하여 문맥을 이해하는 데 필수적이다.

셀프 어텐션 기법은 다음과 같은 과정을 포함한다.
1. 쿼리, 키, 값 생성: 각 단어의 임베딩 벡터를 기반으로 쿼리, 키, 값 벡터를 생성
2. 어텐션 스코어 계산: 쿼리와 모든 키 간의 유사도를 계산하여 어텐션 스코어를 생성
3. 스코어 정규화: 소프트맥스 함수를 사용해 스코어를 정규화하여 각 단어의 중요도를 할당
4. 가중합: 정규화된 스코어를 값 벡터에 곱하여 최종적인 출력 벡터를 생성
이러한 과정을 통해 모델은 입력 문장의 문맥을 깊이 있게 이해하고, 다음 단어를 예측하거나 문장을 생성하는 데 필요한 정보를 종합한다.
3. 대표적인 LLM 모델
- Chat GPT (Open AI) - OpenAI에서 개발한 대화형 AI 모델로 대규모 텍스트를 사전 학습하여 다양한 언어 생성 및 이해 작업을 수행할 수 있다. 이 모델은 사용자와의 자연스러운 대화를 위해 최적화되어 있으며, 다양한 언어에서 높은 정확도를 자랑한다.
- Gemini (Google) - 구글의 최신 LLM으로 멀티모달 데이터를 처리할 수 있는 기능을 갖추고 있다. 즉, 텍스트와 이미지를 동시에 이해하고 생성할 수 있는 능력을 제공한다. 특히 정보 검색과 대화에서 효과적인 성능을 보인다.
- Claude (Anthropic) - Anthropic에서 개발한 모델로 인간과의 상호작용에서 안전성과 윤리성을 고려하여 설계되었다. 이 모델은 특히 대화형 AI로서의 기능에 특화되어 있으며, 사용자와의 신뢰를 구축하는 데 중요한 역할을 한다.
- Llama (Meta) - Meta에서 개발한 모델로 오픈 소스로 제공되어 다양한 연구 및 응용 분야에서 활용되고 있다. Llama는 연구자와 개발자들이 자유롭게 접근하고 수정할 수 있는 기반을 제공하여 협업과 혁신을 촉진한다.
4. 결론
LLM은 자연어 처리 분야에서 혁신적인 변화를 가져온 기술로 앞으로의 연구와 발전이 기대된다. 현재 다양한 산업에서의 응용 가능성이 높아지고 있으며 앞으로도 계속 발전할 것으로 예상된다. 이러한 LLM을 더욱 효율적이고 안전한 방향으로 발전하기 위해서는 AI 윤리 및 규제에 대한 논의도 활발해져야 할 것이다.
'Research' 카테고리의 다른 글
| [RAG] RAG란 무엇인가? (0) | 2025.03.06 |
|---|